
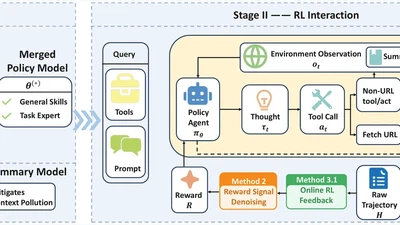
AgentCPM-Explore: Realizing Long-Horizon Deep Exploration for Edge-Scale Agents
ArXiv 2026. First author. Open-source 4B agent model achieving SOTA on GAIA & HLE, surpassing GPT-5 and Claude-4.5-Sonnet.
PhD in Data Science
2018-09-01
2024-06-30
Fudan University
BEng in EE
2014-09-01
2018-06-30
Dalian University of Technology
Shanghai Jiao Tong University
Tsinghua University
Microsoft Research Asia
Tsinghua University (IIIS)
Fudan University
Dalian University of Technology
I study how to build AI systems that can automate long-horizon work in research, engineering, and development. A central goal of my work is to make data-driven scientific research more scalable, reliable, and productive. I currently focus on three closely connected directions:
🧪 AI4Research — I build AI research assistants for literature retrieval, experiment design, data analysis, and hypothesis generation and verification.
🤖 Autonomous Agents — I develop agent models and systems with environment perception, memory, planning, and tool-use capabilities, with LLMs as the core intelligence.
🧠 Foundation Models — I explore how to train and adapt general-purpose models for language understanding, knowledge representation, multimodal fusion, and downstream generalization.
ArXiv 2026. First author. Open-source 4B agent model achieving SOTA on GAIA & HLE, surpassing GPT-5 and Claude-4.5-Sonnet.
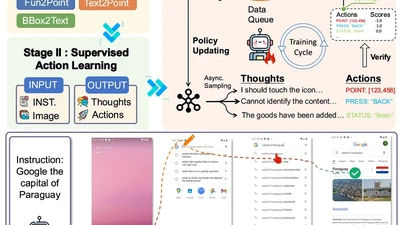
EMNLP 2025 Demo. GUI agents with reinforcement fine-tuning. 1,200+ GitHub Stars.

ArXiv 2025. Team contribution (led MCP agent capabilities). 8,300+ GitHub Stars.
ArXiv 2024. First author. RD-Agent for automatic R&D. Featured in Microsoft Build 2025 Keynote. 11,400+ GitHub Stars.
All my open-source contributions revolve around the central theme of LLM-powered agents, forming a cohesive ecosystem: Data (AgentCPM-GUI) → Algorithm (AgentRL, AgentCPM-Explore, MiniCPM4-MCP) → Execution (RD-Agent) → Evaluation (ToLeaP).
🔬 **Core Founding Member & Primary Coder** · I helped build an automated R&D agent for data science and finance …
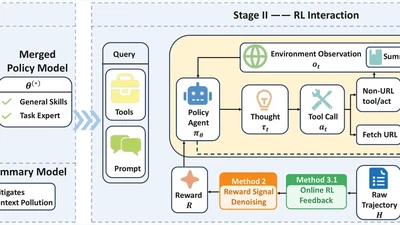
🏆 **Project Lead** · I led an open-source 4B agent model for long-horizon deep exploration …

🏆 **Project Lead** · Fully asynchronous agent RL training infrastructure for the AgentCPM model family `100+ Tools` · `20+ Benchmarks` · `Full-cycle Visualization`


🏆 **Project Lead** · Edge-scale (8B) agent LLM mastering MCP tools [](https://github.com/OpenBMB/MiniCPM) …
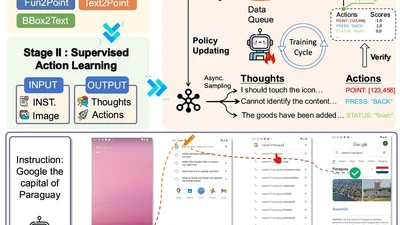
📱 **Training Data Lead** · Multimodal LLM-based GUI agent for mobile & desktop …
🧑🏫 Student Supervision — I co-supervise undergraduate, master’s, and PhD students on LLM agents and data mining.
📝 Conference Reviewing — I regularly review for venues including NeurIPS, ICLR, EMNLP, KDD, WWW, and COLING.
📰 Journal Reviewing — I have also reviewed for journals such as TKDE, Science China, and AI Open.
🎤 Invited Talks — Recent invited talks include Autonomous Agents and Tool Learning with LLMs (RLChina 2025) and LLM-Driven Autonomous Agents (Huawei OpenHarmony AI Agent TSG).
💰 Research Grants — I currently serve as PI for the China Postdoctoral Science Foundation General Grant and the National Postdoctoral Researcher Program Category C.
Feel free to reach out if you would like to discuss research ideas, collaborations, or open-source projects.
✉️ Email: haotian.chen@163.com / ht1ian.chen@gmail.com
🐙 GitHub: github.com/Hytn
✖️ X: @HytnChen
🎓 Google Scholar: scholar profile