AI for Finance
 The Research Plan of the Project Drafted by Haotian Chen
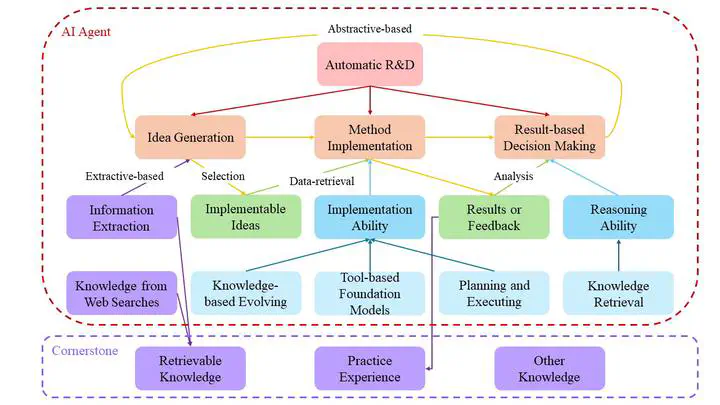
The Research Plan of the Project Drafted by Haotian ChenThe figure shows my drafted structure of future work and its underlying logic in conducting Data-Centric Automatic R&D research, where ideas can be replaced by factors in financial scenarios.
The overall assumption is that knowledge will facilitate the performance of AI Agent in Automatic R&D. Here comes three questions: Q1: What’s the mission of AI Agent in automatic R&D? Q2: What is knowledge? Q3: How to use knowledge to empower AI Agent?
A1: As shown in the orange blocks, I assume that there’re three crucial (even necessary) steps in realizing automatic R&D: Idea generation, method implementation, and making decisions based on experimental results. The three steps form the life cycle of automatic R&D. I hope that AI Agents can follow the cycle and be well-performed in each step. I believe that such an agent can push the frontiers of R&D. Here’re the detailed definitions of the three steps.
Idea Generation: I consider all the ideas to be generated in two ways: extractive or abstractive. This is similar to the traditional classification of text generation methods. Extractive-based idea generation means that we can find ideas from the raw data (e.g., papers, websites, reports, etc.) by information extraction: All the ideas are recorded or mentioned in the raw data. What AI agents should do is to distinguish and then extract them (sometimes can even complete/create ideas by “hallucination”). Abstractive-based idea generation aims to find new ideas from the experimental results. AI agents will make decisions about what to implement in the next round for more “informative” experimental results. The more informative the results are, the greater information entropy or variance they will reduce (quantitative evaluating “informative”).
Method Implementation: I regard “methods” as the “implementable” ideas expressed by formulations and models. To successfully implement these methods, AI agents should first accurately find the corresponding data according to the given data introduction or background description. Second, they use their implementation ability to obtain the results of these methods. Note that not all experimental attempts will be successful, so sometimes they get feedback from the environment (e.g., the error reported by python or code evaluator) instead of final results.
Result-based Decision Making: After obtaining all the results or feedbacks, AI Agents will decide what to implement (come up with some ideas) in the next round (i.e., an attempt) or next several round (i.e., a plan). They will use their reasoning ability to find clues/logic/evidence information that can reveal what to do next.
A2: As I mentioned in A1, AI Agents have to possess many strong abilities to tackle automatic R&D elegantly because the task is so difficult. Given that humans have accumulated thousands years of experience (knowledge) in this task, so let’s equip AI agents with knowledge! I think that the valuable knowledge comes from three sources:
Retrievable knowledge: We can get retrievable knowledge directly from the publicly available information. I give two examples here. One is the by-product of Extractive-based Idea Generation (i.e., knowledge extracted by information extraction). The other is knowledge from web searches. There’re many LLMs perform well in fetching the two kinds of knowledge.
Practice Experience: I think an example of the typical practice experience is the feedbacks from environments: Different types of errors raised by python or reported in the comparison with ground-truth results.
Other Knowledge: There’s also some knowledge that can neither be retrieved directly from raw information nor practice experience, such as private data, industry-specific knowledge graph, or the deep insights and understandings formed by reading hundreds of papers. Such kind of knowledge need to be manually instilled into AI agents.
A3: With the support of sufficient knowledge, AI agents are ideally able to use it to improve their extraction ability, implementation ability, and reasoning ability. Specifically, current SOTA solutions focus on pretraining (Tool-based LLMs) or planning (e.g., CoT, React, etc.), neglecting to 1) collect the valuable information in previous feedbacks; 2) retrieve the corresponding knowledge in the current step to make a step further towards the correct answer instead of giving up the current dialogue; 3) retrieve knowledge to custimize the prompt in each interaction. Our proposed knowledge-based evolving depicts a promising framework to unify and extend the logic of current solutions.
Consequently, I think it’s interesting to push such a direction. During the process, we’ll get many observations and findings. Perhaps we can further find the underlying regularity among the issues of current SOTA ML systems. This will deepen our insights and help us to propose more effective solutions.
Haotian Chen
Researcher in Artificial Intelligence
My research interests include automatic machine learning, trustworthy AI, information extraction.