Information Extraction and Management on Textual Data
 The Research Plan of the Project Drafted by Haotian Chen
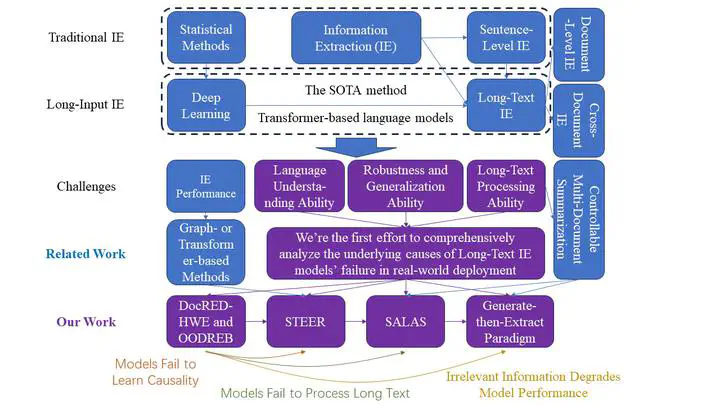
The Research Plan of the Project Drafted by Haotian ChenRelation extraction technology is a core foundational technology that empowers intelligent information services and artificial intelligence research. The automated extraction of structured information for building knowledge bases endows intelligent agents with capabilities such as logical reasoning and deep text comprehension, significantly advancing their performance in various real-world text processing tasks. High-quality knowledge bases are characterized by richness and accuracy of knowledge, thus posing a dual demand on relation extraction technology: accuracy and enrichment of extracted information. Traditional relation extraction techniques mainly focus on short-text relation extraction within single sentences. However, a substantial portion of human knowledge and information is stored in long texts, necessitating the development of long-text relation extraction methods through cross-sentence reasoning to unearth the inter-sentential relations and thereby enhance the richness of knowledge in databases. Moreover, long-text relation extraction methods must be deployable in open-domain, real-world scenarios, achieving accurate relation extraction through correct semantic understanding and processing, thereby improving the accuracy of knowledge in databases. Current research on long-text relation extraction technology, from evaluation benchmarks to technical routes, is still in the preliminary exploration stage. The evaluation benchmarks play a guiding role in the direction of technical routes, making systematic and comprehensive research on long-text relation extraction techniques of significant importance.
Our work starts with the completion and reconstruction of evaluation benchmarks for long-text relation extraction methods, rethinking and demonstrating the impact of the semantic understanding level of relation extraction methods on their real-world application performance. Based on new insights, it identifies the main challenges in developing long-text relation extraction methods deployable in real scenarios: the one-sidedness of current evaluation benchmarks, the excessive redundancy in long texts, the lack of data governance, and the structural inability of long-text relation extraction models to distinguish causal information (lack of human prior knowledge). Our work addresses these challenges by reconstructing and developing long-text relation extraction methods. The main contributions of this work include:
Establishing a comprehensive and complete evaluation benchmark for long-text relation extraction methods, providing a basis for subsequent research directions through extensive experiments and analysis. Specifically, this work first constructs an evaluation benchmark for the language understanding ability of long-text relation extraction methods, and introduces a benchmark for evaluating the out-of-distribution generalization capability of these methods. By analyzing and characterizing the language understanding ability of current state-of-the-art deep learning-based long-text relation extraction models, it reveals that these models learn numerous false associations (pseudo-associations) between non-causal information and prediction results, significantly weakening the models’ robustness and generalization capabilities, and forming uninterpretable decision-making bases within the models. The work demonstrates the unreliability of these models’ decision bases through six types of attacks aimed at relation extraction and introduces new evaluation metrics to measure models’ language understanding and reasoning capabilities. The final analysis shows that the degree of understanding of human decision bases in long-text relation extraction methods should be included in the evaluation, guiding the development of the next generation of methods. Otherwise, such methods will not be deployable in real application scenarios. Two papers are accepted by ACL2023 and WWW2024, respectively.
Proposing a Suppress-Then-EnhancE Representation learning method (STEER), to improve its document-level relation extraction performance. STEER not only avoids the prohibitively expensive cost of human-annotated evidence information in real-world scenarios but also focuses on fine-grained word-level evidence instead of the commonly adopted coarse-grained sentence-level evidence. Specifically, we identify the semantic magnitude of each word through our proposed reinforcement learning method followed by an evidence amplifier. The former suppresses the influence of those words with marginal semantic contribution in an unsupervised way, while the latter amplifies the influence of evidence words by leveraging prior knowledge. Extensive experimental results demonstrate that our proposed STEER improves the OOD generalization ability of most SOTA DocRE methods and achieves the SOTA OOD generalization performance on six commonly used RE datasets. This work will be submitted to EMNLP2024.
Addressing the issue of excessive redundant information in long texts and lack of data governance, this work proposes an entity-guided multi-document information summarization method. Specifically, for complex scenarios like cross-document relation extraction that involve hidden relational directional information and require large-scale reasoning based on related information, this work introduces a new processing paradigm. It first summarizes the extremely long texts, and then extracts relationships based on the summarized information. For long-text information summarization, the work proposes a new entity-guided summarization method that dynamically captures, compares, and monitors the amount of entity-related information contained in the input text and the output summary. It also introduces an entity information loss function to simultaneously constrain the learning process of the generative model and enhance text representation capabilities. This enables the method to generate summaries containing as much entity information as possible, aiding subsequent relation extraction from the summarized text information. The method achieves optimal performance on three public multi-document text summarization datasets, proving its exceptional entity information summarization effect. This work is accepted by ECML-PKDD 2023.
Proposing an entity-guided human decision-making basis generation cross-document relation extraction method, significantly enhancing the performance of long-text relation extraction methods in the most complex cross-document relation extraction scenarios. Following the new processing paradigm proposed in the third point, to significantly reduce the difficulty of learning human decision bases in relation extraction models in scenarios with redundant information and scarce human decision basis annotations, this work further improves the entity information summarization method. By proposing a generator revolving around entities capable of generating text information close to human decision bases, long-text relation extraction models can further learn from the generated text, greatly improving the models’ generalization capabilities and robustness. Experimental results show that the performance of long-text relation extraction models trained with this generate-then-extract paradigm significantly outperforms models trained without this paradigm. Additionally, the performance of the generate-then-extract method based on the entity-centered generator is significantly better than that based on other current state-of-the-art generators. This work is under-review in KDD2024.
Haotian Chen
Researcher in Artificial Intelligence
My research interests include automatic machine learning, trustworthy AI, information extraction.