AgentCPM-Explore
🏆 **项目负责人** · 我主导了一个面向长程深度探索的开源 4B 智能体模型 [](https://github.com/OpenBMB/AgentCPM)
•
1 min read
🏆 **项目负责人** · 我主导了一个面向长程深度探索的开源 4B 智能体模型 [](https://github.com/OpenBMB/AgentCPM)
🏆 **Project Lead** · I led an open-source 4B agent model for long-horizon deep exploration …
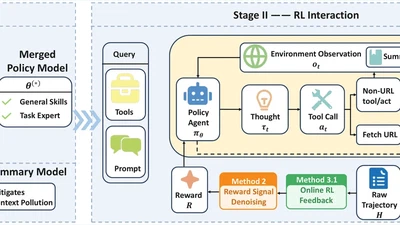
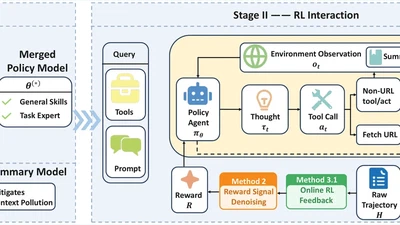
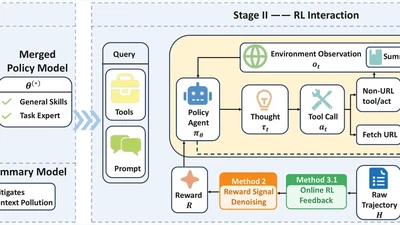
ArXiv 2026. First author. Open-source 4B agent model achieving SOTA on GAIA & HLE, surpassing GPT-5 and Claude-4.5-Sonnet.
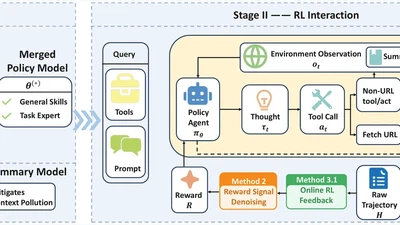
ArXiv 2026. First author. Open-source 4B agent model achieving SOTA on GAIA & HLE, surpassing GPT-5 and Claude-4.5-Sonnet.
Submitted to ACL 2026. Reflective reinforcement learning for tool learning.
Submitted to ACL 2026. Reflective reinforcement learning for tool learning.


🏆 **Project Lead** · Fully asynchronous agent RL training infrastructure for the AgentCPM model family `100+ Tools` · `20+ Benchmarks` · `Full-cycle Visualization`
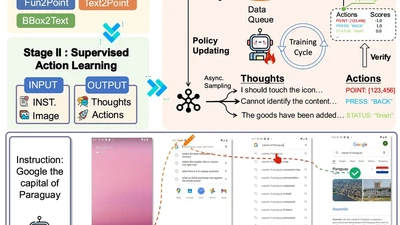
EMNLP 2025 Demo. GUI agents with reinforcement fine-tuning. 1,200+ GitHub Stars.
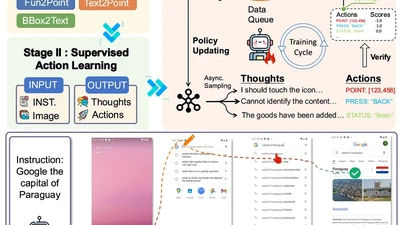
EMNLP 2025 Demo. GUI agents with reinforcement fine-tuning. 1,200+ GitHub Stars.